On October 23, 2025, the Whiting School of Engineering’s Department of Computer Science at Johns Hopkins University hosted a significant lecture by Aaron Roth, a professor specializing in computer and cognitive science at the University of Pennsylvania. The talk, titled “Agreement and Alignment for Human-AI Collaboration,” presented findings from three pivotal papers, including “Tractable Agreement Protocols” and “Collaborative Prediction: Tractable Information Aggregation via Agreement.”
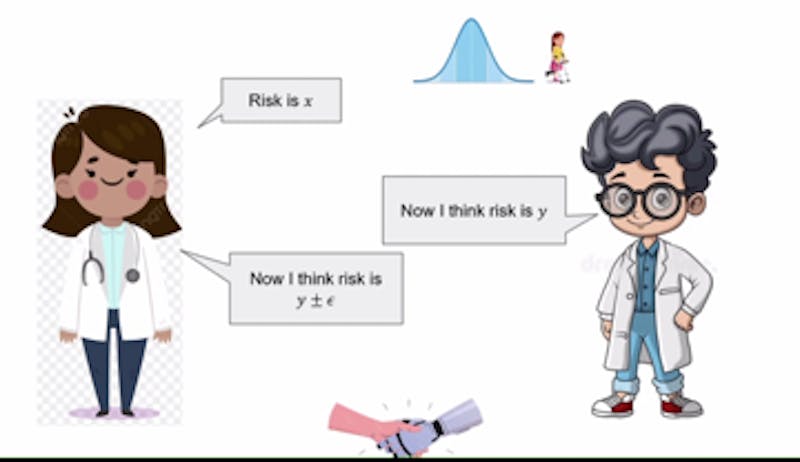
Roth’s presentation addressed the growing importance of artificial intelligence in various sectors, particularly its role in assisting human decision-making. He illustrated this by discussing AI’s potential to aid doctors in patient diagnosis. In this scenario, AI analyzes data such as previous diagnoses and symptoms, generating predictions for the physician to consider. The doctor subsequently evaluates these predictions, leveraging their clinical expertise.
The process is not without its challenges. Roth explained that if a disagreement arises between the AI’s recommendations and the doctor’s conclusions, both parties can engage in a structured dialogue, reiterating their perspectives over a limited number of rounds. This iterative process allows them to incorporate each other’s insights, ultimately working towards a consensus. This form of collaboration hinges on the concept of a “common prior,” where both the AI and the doctor share foundational assumptions about the situation, despite having different specific knowledge.
Roth termed this collaborative agreement as Perfect Bayesian Rationality. In this framework, each party recognizes that the other possesses valuable information, enabling them to reach an understanding. However, he acknowledged that establishing a common prior can be complex due to the intricate nature of real-world scenarios, particularly in multifaceted areas like healthcare diagnostics.
Calibrating Conversations for Better Outcomes
To facilitate productive discussions, Roth introduced the concept of calibration, drawing an analogy to weather forecasting. He described how calibration can serve as a metric for assessing the accuracy of predictions. For example, if an AI assesses a treatment risk at 40% and the doctor estimates it at 35%, the AI’s subsequent claim would adjust to fall between these two figures. This calibration process continues until both parties reach an agreement.
Roth emphasized that this model assumes both the AI and the doctor have aligned goals. However, complications can arise, particularly when the AI is developed by a pharmaceutical company. In such cases, the AI may be biased towards promoting its own products. Roth advised that in these situations, doctors should consult multiple large language models (LLMs) from different companies. By doing so, physicians can aggregate insights from various sources, promoting competitive dynamics that encourage alignment and reduce bias in AI recommendations.
Roth concluded the discussion by exploring the notion of real probabilities, which reflect the true dynamics of the world. While these probabilities offer the most precise insights, he noted that such accuracy is often unnecessary. Instead, unbiased probabilities derived from limited data can suffice for effective decision-making.
Through this collaborative framework, Roth posits that doctors and AI can forge agreements on optimal treatments, diagnoses, and more. This evolving dialogue between human expertise and machine learning has the potential to enhance healthcare outcomes and improve patient care in the future.