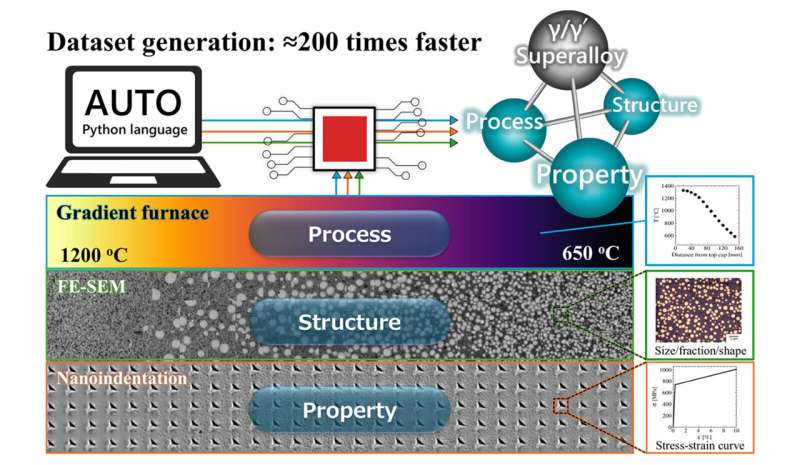
A research team at the National Institute for Materials Science (NIMS) has developed an innovative automated high-throughput system designed to generate extensive datasets from a single sample of a superalloy used in aircraft engines. This advanced system has successfully produced a substantial experimental dataset within just 13 days, a process that would typically take over seven years using traditional methods.
The automated system is capable of delivering detailed Process–Structure–Property datasets, which encompass thousands of records. Each record includes crucial information such as interconnected processing conditions, microstructural features, and resulting yield strengths. The efficiency of this system allows for the rapid production of large-scale datasets, significantly accelerating the pace of data-driven materials design.
Transforming Materials Science
High-precision experimental data is vital for exploring material mechanisms and developing new theories and models. These datasets are essential for optimizing the processing methods of heat-resistant superalloys and understanding their complex, multi-element microstructures. Traditionally, the generation of such extensive databases has required years of persistent experimental work and considerable resource investment, presenting significant challenges to the development of high-performance superalloys.
The NIMS research team focused on a Ni-Co-based superalloy, specifically designed for use in aircraft engine turbine disks. By utilizing a gradient temperature furnace developed by the team, they were able to thermally treat the superalloy sample across a range of processing temperatures. This method enabled the collection of data on precipitate parameters and mechanical properties, such as yield stress, at various coordinates along the temperature gradient.
Measurements were conducted using a scanning electron microscope, which was automatically controlled via a Python API, alongside a nanoindenter. The system efficiently evaluated and processed the gathered data, resulting in an impressive volume of Process–Structure–Property data in a fraction of the time required by conventional approaches.
Future Applications and Goals
Looking ahead, the research team plans to apply this automated system to the development of databases for various target superalloys. They aim to enhance technologies for acquiring high-temperature yield stress and creep data, which are crucial for materials design. Additionally, the team intends to formulate multi-component phase diagrams based on the constructed superalloy databases, further driving innovation in this field.
Another significant goal is to explore new superalloys with desirable properties through data-driven techniques. Ultimately, the team aspires to fabricate new heat-resistant superalloys that could play a vital role in efforts towards achieving carbon neutrality.
This groundbreaking research has been documented in the journal Materials & Design. For more information, refer to the article by Thomas Hoefler et al, titled “Automated system for high-throughput process-structure-property dataset generation of structural materials: A γ/γ′ superalloy case study,” published on November 11, 2025. The work underscores the potential of automated systems to revolutionize materials science by enabling faster and more efficient data generation, thus paving the way for innovative developments in superalloy technology.